

Comment Scraper un site web avec Scrapy
Scrapy est un framework de python qui permet de crawler des sites web et d’extraire des données structurées qui peuvent être utilisées pour faire d’autres choses comme le data mining, le traitement de l’information ou l’archivage historique.
Même si Scrapy a été conçu à l’origine pour le scraping web, il peut également être utilisé pour extraire des données à l’aide d’API (comme Amazon Associates Web Services) ou comme un crawler web à usage général.
Cas pratiques:
Nous allons voir comment utiliser les spider de scrapy pour scraper les titres, a meta description des balise H1 et H2 d’un site web.
Nous supposons que nous avons tous installé Python et un éditeur( vs code) sur nos ordinateurs.
Nous devons d’abord installer scrapy sur notre ordinateur en exécutant le code suivant:
pip install Scrapy
Avant de commencer le scraping, vous devez créer un nouveau projet Scrapy. Entrez un répertoire dans lequel vous souhaitez sauvegarder votre code et exécutez :
scrapy startproject tutorial
Nous allons maintenant créer le spider qui nous permettra de crawler notre site web.
Voici le code de notre premier Spider. Enregistrez-le dans un fichier nommé first_spider.py sous le répertoire tutorial/spiders de votre projet :
import scrapy
class firstSpider(scrapy.Spider):
name = ‘firstSpider’
start_urls = [‘https://tenteeglobal.com/’]
def parse(self, response):
title = response.xpath(“//title/text()”).extract()
count_title = len(title[0])
description = response.xpath(“//meta[@property=’og:description’]/@content”).extract_first()
count_description = len(description) if description else 0
h1 = response.xpath(‘//h1//text()’).getall()
h2 = response.xpath(‘//h2//text()’).getall()
robot = response.xpath(“//meta[@name=’robots’]/@content”).extract_first()
download_time = response.meta[‘download_latency’]
yield {
‘Title’: title,
‘Title count’: count_title,
‘Meta description’: description,
‘Meta description count’: count_description,
‘H1’: h1,
‘H2’: h2,
‘Robot’: robot,
‘Download time’: download_time
}
Pour mettre notre spider au travail, allez dans le répertoire de base du projet et exécutez :
scrapy crawl firstSpider -o firstSpider.json
Et le résultat c’est un fichier json qui contient les données scraper
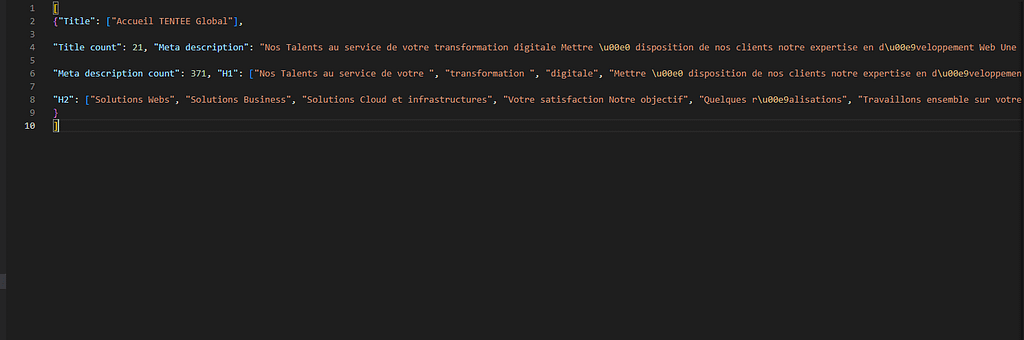
Resumé
Le processus de scraping web avec scrapy se résume aux étapes suivantes :
● Installer python et un éditeur approprié par exemple VS Code sur votre
machine
● Puis installez scrapy avec l’aide de du code: pip install Scrapy
● Démarrez un nouveau projet a l’aide de scrapy startproject tutorial
● Créez un spider comme indiqué ci-dessus
● Enfin, exécutez le code
● scrapy crawl firstSpider -o firstSpider.json
et obtenez vos résultats.